
Azure Service Bus
October 18, 2025
azuredevopsmessagingAzure Service Bus: Routing, Sessions as Index, and Atomicity
When I first used Service Bus, I thought it was “just a queue.” It’s much more: routing, ordering, retries, DLQ, transactions—useful for high‑volume, near real‑time integrations.
Service Bus in 60 seconds
- Queues: point‑to‑point.
- Topics & Subscriptions: pub/sub with SQL filters on message properties.
- Sessions: FIFO per key (keeps order for a customer/order).
- Retries & DLQ: auto‑retries; poison messages move to DLQ.
- Extras: duplicate detection, scheduled delivery, deferral, transactions.
Using Service Bus in Modern Architectures
I’m highlighting three common use cases that are easily handled with queues and topics.
1. Event‑Driven Architecture with Routed Messages
Scenario: accept requests, fan‑out by properties, and keep downstreams isolated.
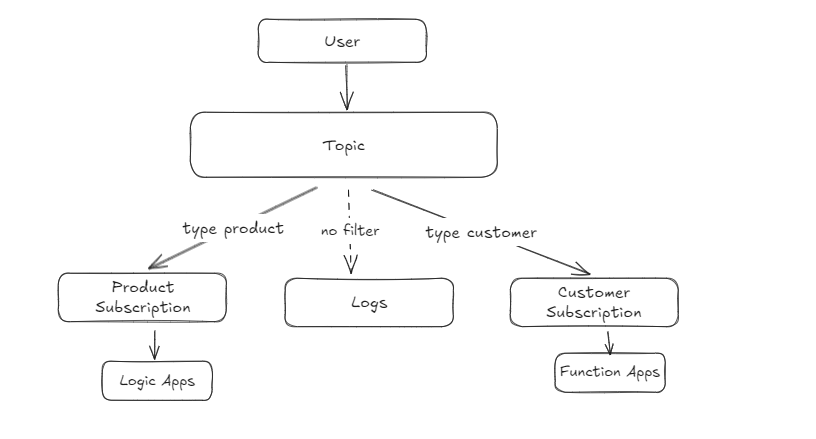
For an asynchronous inbound flow, let’s say we expose a topic on the public internet where a client can send messages. Based on custom metadata (for example, a type property), if type is ERP_PRODUCT_MASTER it goes to the product subscription; if type is ERP_CUSTOMER_MASTER it goes to the customer subscription. Messages are filtered into their respective subscriptions. Additionally, if a subscription needs to receive all events on the topic, omit the filter—product events will go to both the logs subscription and the product subscription, and customer events will go to both the logs subscription and the customer subscription.
2. Sessions as a Keyed Index (the “HashMap” trick)
Most docs talk about sessions for strict ordering. You can also use a session as a single‑item, keyed bucket for quick lookups.
Imagine a transactional flow where you store the data in Service Bus and keep only a reference to that message in the client system. When the client later sends the reference, you need to fetch the message from Service Bus. There are many ways to do this, but the simplest method I found was to use sessions.
How I applied it:
- Set
SessionIdto a business key (e.g.,REF-123). - Store one message per session (acts like a key → value).
- The consumer accepts the session with that ID to fetch the one message directly.
Why it helped:
- No scanning/deferring through many messages.
- Avoids long lock durations while you hunt for the right payload.
3. Transactional Atomicity
Goal: process a batch atomically; complete only on success.
- Receive in peek‑lock, do work, then
complete. - On transient failure:
abandon(retry). - On business retry later:
defer(preserve it for targeted pickup). - On poison: let it exceed max deliveries → DLQ.
Notes:
- Tune
MaxDeliveryCountfor the right balance of retry vs. fast DLQ. - Renew locks if processing may exceed
LockDuration. - Idempotent handlers are essential (at‑least‑once delivery).
Ops and Security Tips
- Enable duplicate detection if producers can retry sends.
- Alerts: DLQ count > 0, retry spikes, handler failures.
- Networking: Premium tier for VNet/private endpoints where possible.
- Auth: Managed identities/App Registrations over SAS when you can.
- Logging: log
CorrelationIdand business keys; avoid payload logging.
This was mostly theoretical, but if you want configuration‑focused docs, let me know.
Thanks for reading—keep learning, keep growing.
Reach me via contact.